Intro
Have you ever wondered what happens when you type in a URL and hit enter? The journey of a URL from your browser to the server is a complex process that involves several steps, including DNS lookup, establishing a TCP connection, and making HTTP requests. In this blog, we will demystify this journey and explain each step in detail. We will also discuss how this process is further complicated when using HTTPS and how modern browsers optimize the process to improve efficiency. Understanding the journey of a URL can help developers and users alike to troubleshoot issues and optimize website performance. So, let’s dive in!
What URL is made up of?
URL stands for universal resource locator, and it mainly has three parts.
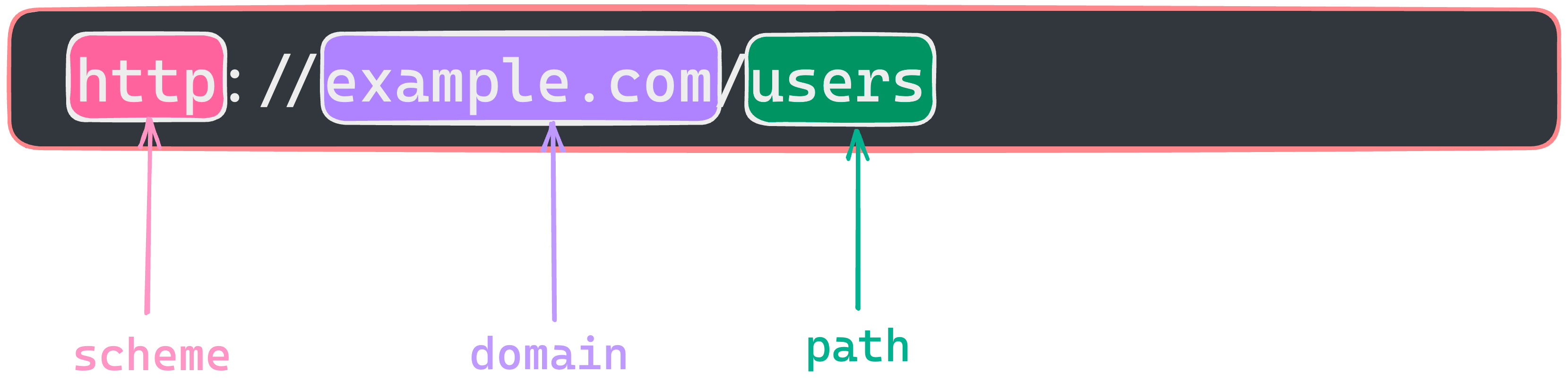
- scheme: The scheme used in this example is “http://,” which signifies that the browser is connecting to the server using the HTTP protocol. HTTP, which stands for Hypertext Transfer Protocol, is a popular protocol for sending data over the internet. When a browser uses “http://” in a URL, it instructs the server to utilise the standard HTTP protocol. HTTPS, which stands for Hypertext Transfer Protocol Secure, is another popular technique.
- domain: The domain name used in this example is ”http://example.com/.” The domain name is a unique address on the internet that identifies a specific website. It is the human-readable name that people can enter into their web browsers to reach a specific website.
- path: The path in a URL, similar to how a file system utilises directories and files to organise and retrieve data, gives a way to travel to a specific resource on a website. It indicates the location on the server of the resource we wish to load.
So okay, let’s say you entered the URL into the browser. What happened next?
As a result, the browser must comprehend how to connect to the server, in this case ”http://example.com/”. This is accomplished through the DNS lookup procedure. DNS stands for Domain Name System, and it functions similarly to a phone directory on the internet. DNS converts domain names into IP addresses, making it possible for browsers to load resources.
DNS data is now extensively cached in order to accelerate the lookup process.
Caching occurs at multiple levels during the DNS resolution process. The browser initially caches DNS data for a limited time. If it cannot find it, it checks the operating system, which temporarily caches it. If the service is still unavailable, the operating system queries a DNS resolver on the internet, initiating a chain of requests to various DNS servers. The answer is cached at each step, optimising the resolution procedure and enhancing DNS infrastructure efficiency.
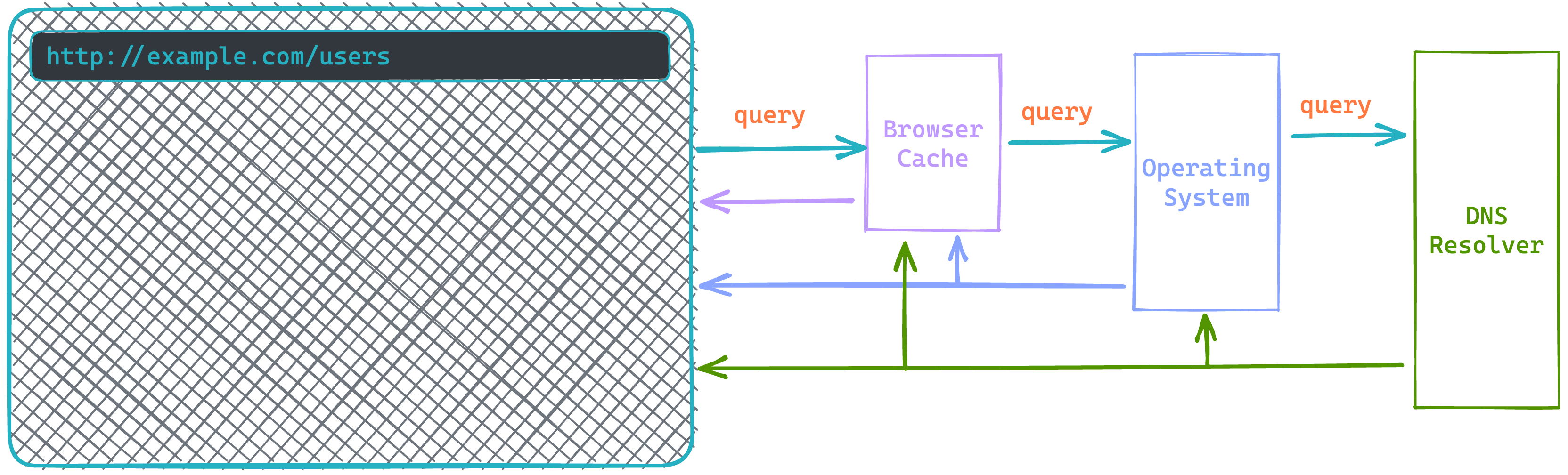
Ultimately, the browser obtains the server’s IP address. The browser then establishes a TCP connection to the server using the IP address it was given. To establish a TCP connection, a handshake is now required. This requires a number of network round trips to finish. In order to keep the loading process as quick as possible, modern web browsers use something called a keep-alive connection, which attempts to reuse an established TCP connection to the server as much as possible.
Creating a new HTTPS connection is a complicated process that involves an SSL/TLS handshake to establish an encrypted connection between both the browser and the server. This handshake consumes a lot of resources, so browsers use techniques like SSL session resumption to cut costs. Overall, the procedure for creating a secure HTTPS connection adds complexity and overhead when compared to standard HTTP connections.
Finally, the browser sends a HTTP request to the server via the TCP connection that has been established.
HTTP is a simple protocol used during web communications. After receiving the browser’s request, the server processes it and returns a response. This response includes the requested data or resources, enabling the browser to continue processing and rendering the page for the user.
The browser renders the HTML content after receiving the response. It may contain additional resources that must be loaded, such as JavaScript bundles and images. To obtain these resources, the browser goes through the previously described process of performing DNS lookups, creating TCP connections, and making HTTP requests. This lets the browser to finish retrieving all of the resources required to render the webpage.
Conclusion
In conclusion, the journey of a URL from the user’s browser to the server is a complex process that involves several steps, including DNS lookup, establishing a TCP connection, and making HTTP requests. The process is further complicated when using HTTPS due to the additional steps required to establish a secure connection. However, modern browsers use techniques such as caching and keep-alive connections to optimize the process and improve efficiency. Understanding the journey of a URL can help developers and users alike to troubleshoot issues and optimize website performance.